
AISS Kickoff Event: Anthropic’s Jan Kirchner on Scalable Oversight Research
written by Gülin Alkan ❂ 5 min read time







Last Thursday, AI Safety Saarland (AISS) hosted Jan Hendrik Kirchner, a researcher at Anthropic, for our kickoff event. Kirchner works on where machine learning meets AI safety, focusing on scalable oversight of AI systems and how we can ensure these increasingly capable systems stay aligned with human values and intentions.
Who Is Jan Kirchner?
Before joining Anthropic, the developers of Claude, Kirchner completed a PhD in computational neuroscience at the Max Planck Institute for Brain Research and worked on alignment research at OpenAI. His work covers how humans or less developed models can effectively supervise much more powerful AI systems, exploring topics like weak-to-strong generalization and prover-verifier games.
From Paperclips to Probabilities: The Evolution of Alignment Thinking
Kirchner began his speech by revisiting the famous early paperclip maximizer thought experiment, which was the early illustration of existential AI risk, showing that being smarter doesn't make an AI good or aligned with human values, and that a system can be extremely intelligent yet pursue any arbitrary goal (like paperclips!).
Over time, as AI systems started scaling faster and faster, a more modern concern became sudden capability jumps and that they could make systems uncontrollable before alignment is solved. This led to the conclusion: We must solve alignment before super intelligence, because after that, it's too late.
Today, however, Kirchner argued that the situation might be more nuanced than just concerns of an imminent "intelligence explosion" or AI progress plateauing, proven by this METR data showing a steadier trend.
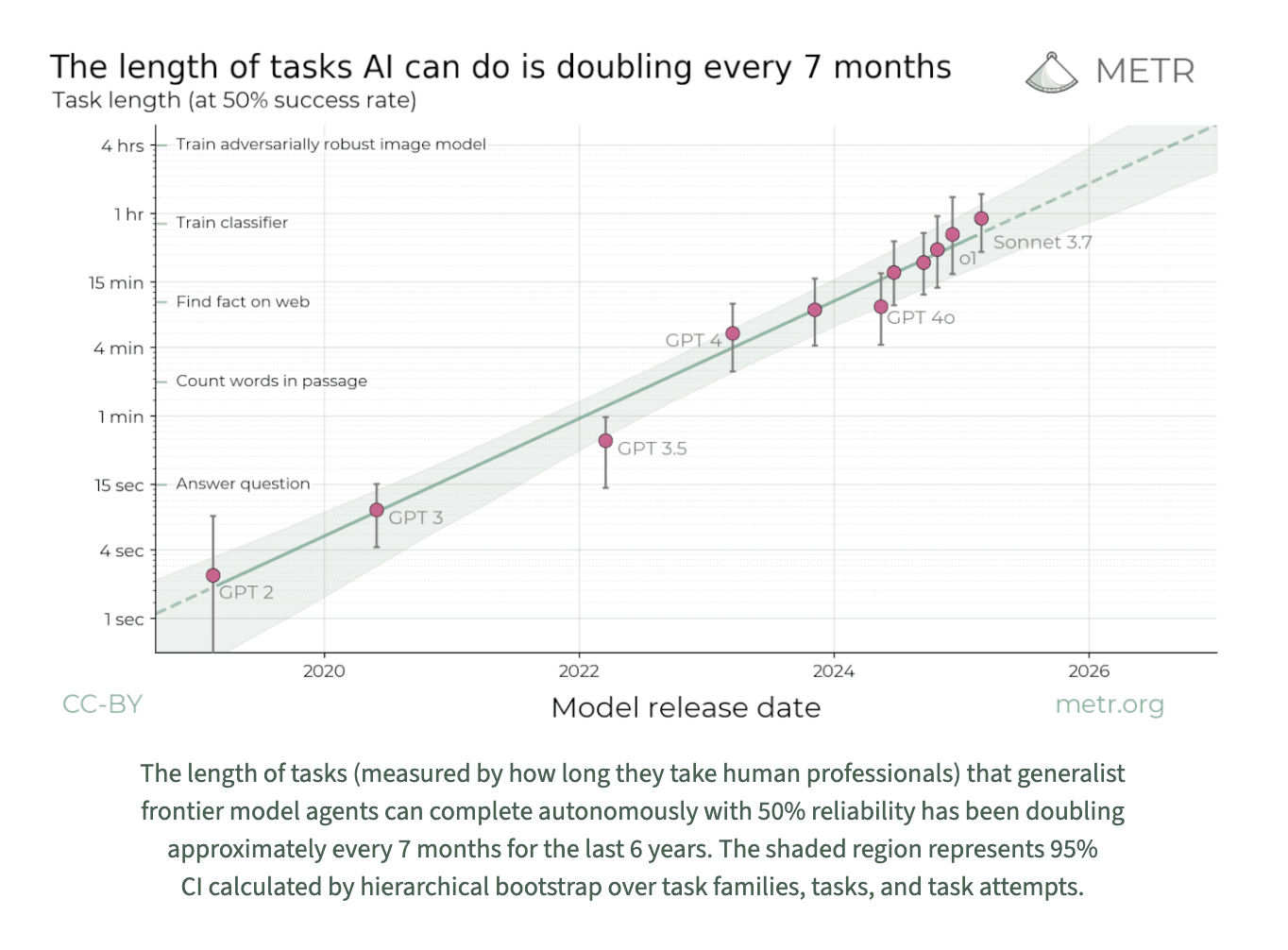
It is important to note that task length is shown on a logarithmic scale.
Contrary to these popular beliefs, this graph shows that every model release from GPT 2 to GPT 5 fits neatly on this smooth curve, implying that progress has been continuous rather than chaotic. This steadiness gives researchers more time: time to improve oversight techniques, build empirical foundations, and plan alignment strategies.
To make use of this time, Kirchner highlighted two current research directions on scalable oversight:
Weak to Strong Generalization
Can a weaker agent, such as GPT-2 or a non-expert human supervisor, effectively supervise a stronger one, such as GPT-4? The results showed, surprisingly, yes.
Through this approach, humans scale their oversight by leveraging weak AI systems or heuristics to supervise stronger systems, showing that even if we can't fully understand or match an AI's intelligence, we can still guide it effectively.
Prover-Verifier Games
This three-player game-like approach works to make AI's reasoning legible and checkable by forcing it to justify its reasoning. It works this way:
Helpful provers explain reasoning clearly.
Sneaky provers try to trick.
Verifiers (human or AI) check proofs.
This approach improves factual accuracy, interpretability, and robustness against adversarial behavior.
Both of these research lines aim to maintain alignment as capabilities scale, rather than solve alignment fully.
The Current Big Picture
Jan Kirchner explains the big picture vision: Automated Alignment Research.
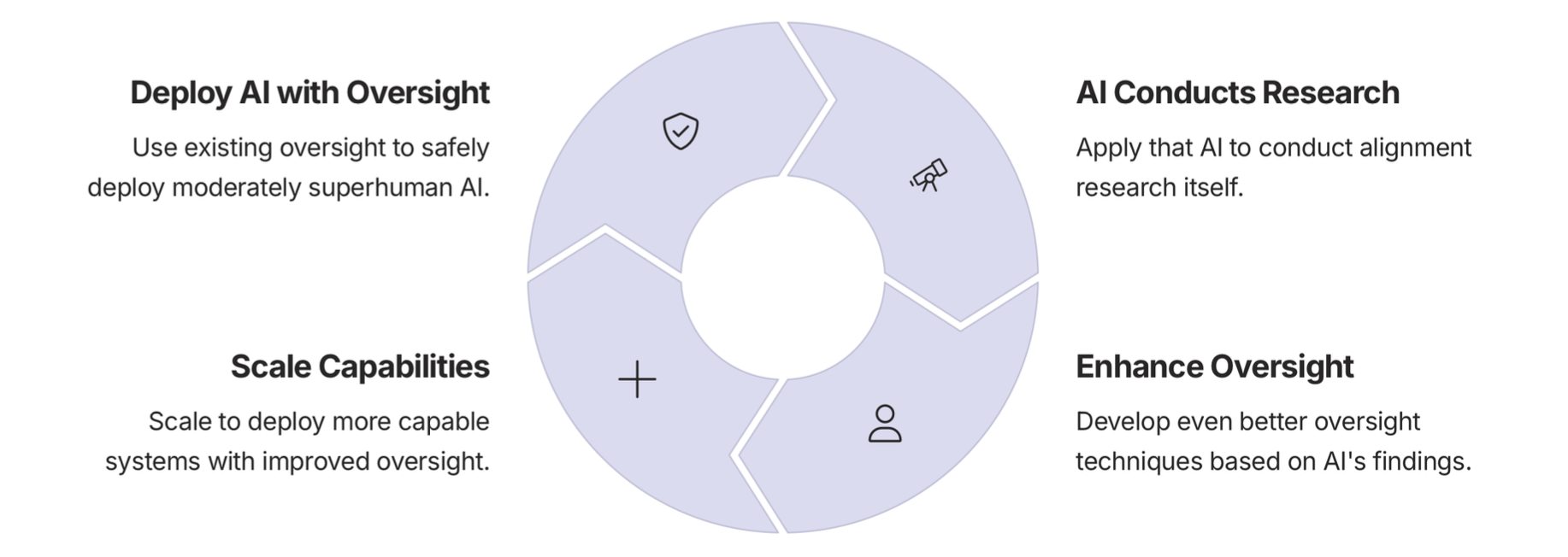
This vision is a self-reinforcing cycle where AI systems work in cooperation with researchers to advance alignment research. It begins with deploying capable AIs under human oversight, making them assist in developing new safety methods, which in turn allows us to supervise even smarter models. The cycle repeats and gradually scales both capability and safety in parallel.
In the long term, the goal is to get to a point where AI goes from something requiring alignment to something that actively builds it. Reinforcement learning systems with long-term reasoning abilities could also eventually sustain this process, turning alignment into a continuous practice, rather than a one time fix.
Conclusion
Kirchner's presentation provided different perspectives through the last 20 years of AI safety concerns and the methodologies we currently use. He was pretty optimistic with his core message, that we have the time, methods and a path forward.
For us at AISS, this kickoff event was a great start to what we aim to accomplish as a society: to foster interdisciplinary exchange, education and research addressing large-scale risks from AI development and deployment, to ultimately contribute meaningfully to this effort. We believe that making AI safe requires collaboration across disciplines to be able to explore the multilayered implications of these systems.
About Us

We're a student-led initiative at Saarland University passionate about AI safety and how we can make a difference. We bring together curious and impact driven minds across disciplines to get involved in solving these challenges through research, education and collaboration.
Interested? Check out how you can continue the conversation and get involved in making AI safer for everyone at AI Safety Saarland.
Further Reading
To dive deeper into Jan Kirchner's work and the topics discussed:
Weak-to-Strong Generalization: Burns et al., 2023 - "Weak-to-Strong Generalization: Eliciting Strong Capabilities With Weak Supervision"
Scalable Oversight: Research from Anthropic on constitutional AI and debate-based oversight methods
Jan Kirchner's Publications: Google Scholar
METR's AI Capability Evaluations: metr.org - For more on tracking AI progress
The slides used in this presentation can be obtained upon request! Please send us an email.
Are you interested in AI safety and want to contribute to the conversation by becoming a writer for our blog? Then send an email to caethel(at)ais-saarland(dot)org with information about yourself, why you’re interested and a sample writing.